
The “Fake News” Phenomenon
Recent years have seen the rise of social media, which have enabled people to share information with a large number of online users, without quality control. On the bright side, this has given the opportunity for everybody to be a content creator and has also enabled a much faster information dissemination. On the not-so-bright side, it has made it possible for malicious users to spread misinformation much faster, potentially reaching large audiences. In some cases, this included building sophisticated profiles for individual users based on a combination of psychological characteristics, meta-data, demographics, and location, and then micro-targeting them with personalized “fake news” and propaganda campaigns that have been weaponized with the aim to achieve political or financial gains.
False information in the news has always been around, e.g., think of the tabloids. However, social media have changed everything. They have made it possible for malicious users to spread misinformation much faster and potentially reaching large audiences. In some cases, this included building sophisticated profiles for individual users based on a combination of psychological characteristics, meta-data, demographics, and location, and then micro-targeting them with personalized “fake news” and propaganda campaigns that have been weaponized with the aim to achieve political or financial gains. As social media are optimized for user engagement, “fake news” thrive on these platforms, as users cannot recognize them and thus they share them further (this is also amplified by bots). Studies have shown that 70% of the users cannot distinguish real from “fake news”, and that “fake news” spread in social media six times faster than real ones. “Fake news” are like spam on steroids: if a spam message reaches 1000 people, it would die there; in contrast, “fake news” can be shared and eventually reach millions.
Nowadays, false information has become a global phenomenon: recently, at least 18 countries had election-related issues with “fake news”. This includes the 2016 US Presidential elections, Brexit, the recent elections in Brazil. To get an idea of the scale, 150 million users on Facebook and Instagram saw inflammatory political ads, and Cambridge Analytica had access to the data for 87 million Facebook users.
False information can not only influence the outcome of political elections, but it can cause direct life loss. For example, false information on WhatsApp has resulted in people being killed in India, and according to a UN report, false information on Facebook is responsible for the Rohingya genocide. False information also puts people’s health in danger, e.g., think of the anti-vaccine websites and the damage they cause to public health worldwide.
Overall, people today are much more likely to believe in conspiracy theories. To give you an example: according to a study, today 57% of Russians believe USA did not put a man on the Moon. In contrast, when the event actually occurred, despite the Cold War, USSR officially congratulated Neil Armstrong, and he was even invited and visited Moscow!
Note that veracity of information is a much bigger problem than just “fake news”. It has been suggested that “Veracity” should be seen as the 4th “V” of Big Data, along with Volume, Variety, Velocity.
Our Solution: Focus on the Source
Previous efforts towards automatic fact-checking have focused on:
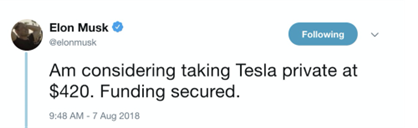

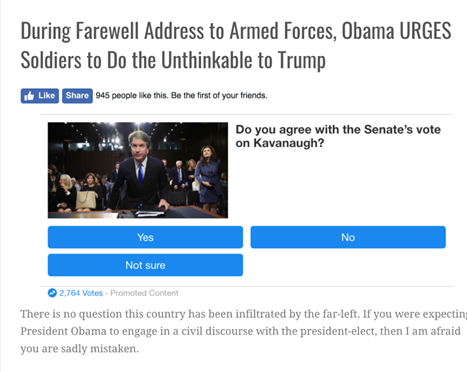
Roughly speaking, to fact-check an article, we can analyze its contents (e.g., the language it uses) and the reliability of its source (a number between 0 and 1, where 0 is very unreliable and 1 is very reliable):
factuality(article) = reliability(language(article)) + reliability(website(article))
To fact-check a claim, we can retrieve articles discussing the claim, then we need to detect the stance of each article with respect to the claim and to take a weighted sum (here the stance is -1 if the article disagrees with the claim, 1 if it agrees, and 0 if it just discusses the claim or is unrelated to it):
factuality(claim) = sum_i [reliability(article_i) * stance(article_i, claim)]
In the former formula, the reliability of the website that hosts an article serves as a prior to compute the factuality of an article. Then, in the latter formula, we use the factuality of the retrieved articles to compute a factuality score for a claim. The idea is that if a reliable article agrees/disagrees with the claim, this is a good indicator for it being true/false; it is the other way around for unreliable articles.
Of course, the formulas above are oversimplifications, e.g., one can fact-check a claim based on the reactions of users in social media, based on spread over time in social media, based on information in a knowledge graph or information from Wikipedia, based on similarity to previously checked claims, etc. Yet, they give the general idea that we need to estimate the reliability of the website on which the article was published. Interestingly, this problem has been largely ignored in previous work, and has been only addressed indirectly.
Thus, we focus on characterizing entire news outlets. This is much more useful than fact-checking claims or articles, as it is hardly feasible to fact-check every single piece of news. It also takes time, both to human users and to automatic programs, as they need to monitor how trusted mainstream media report on the event, how users react to it in social media, etc., and it takes time to get enough of this necessary evidence accumulated in order to be able to make a reliable prediction. It is much more feasible to check the news outlets. That way, we can also fact-check the sources in advance. In a way, we can fact-check the news before they were even written! It is enough to check how trustworthy the outlets that published them are. It is like in the movie “Minority Report”, where authorities could detect a crime before it was committed.
In general, fighting misinformation is not easy; as in the case of spam, this is an adversarial problem, where the malicious actors constantly change and improve their strategies. Yet, when they share news in social media, they typically post a link to an article that is hosted on some website. This is what we are exploiting: we try to characterize the news outlet where the article is hosted. This is also what journalists typically do: they first check the source.
Finally, even though we focus on the source, our work is also compatible with fact-checking a claim or a news article, as we can provide an important prior and thus help both algorithms and human fact-checkers that try to fact-check a particular news article or a claim.
Disinformation typically focuses on emotions, and political propaganda often discusses moral categories. There are many incentives for news outlets to publish articles that appeal to emotions: (i) this has a strong propagandistic effect on the target user, (ii) it makes it more likely to be shared further by the users, and (iii) it will be favored as a candidate to be shown in other users’ newsfeed as this is what algorithms on social media optimize for. And news outlets want to get users to share links to their content in social media as this allows them to reach larger audience. This kind of language also makes them detectable for AI algorithms such as ours; yet, they cannot do much about it as changing the language would make their message less effective and it would also limit its spread.
While analysis of language is the most important information source, we also consider information in Wikipedia, social media, traffic statistics and structure of the target site’s URL:
(i) the text of a few hundred articles published by the target news outlet (e.g., cnn.com), analyzing the style, subjectivity, sentiment, morality, vocabulary richness, etc.
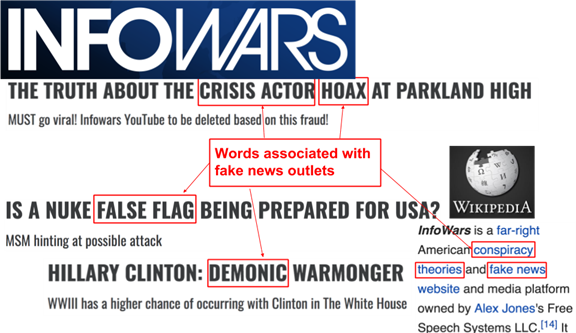
(ii) the text of its Wikipedia page (if any), including its infobox, summary, content, categories, e.g., it might say that the website spreads false information and conspiracy theories:
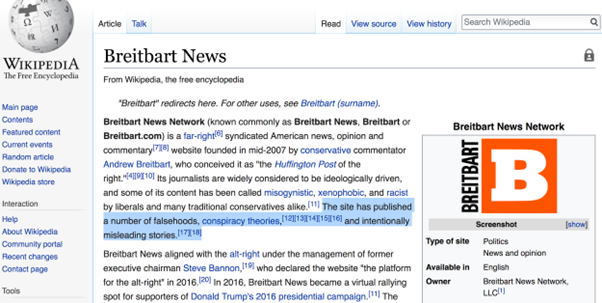
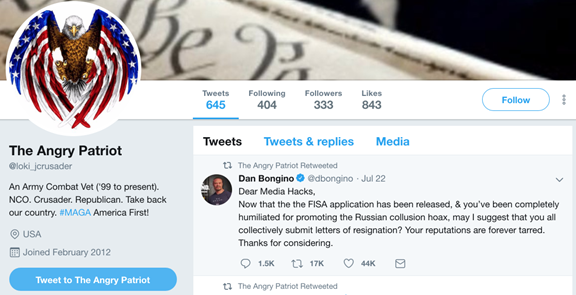
(iii) its Twitter account (if any):
(iv) the Web traffic it attracts, e.g., compare the traffic for the original ABC
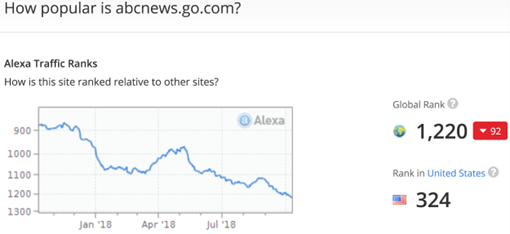
to that for the fake one:
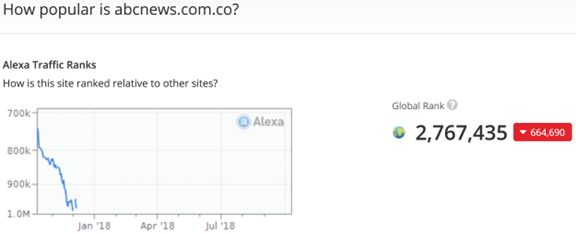
(v) the structure of its URL (is it long, does it contain meaningful words as in http://www.angrypatriotmovement.com/ and http://100percentfedup.com/? Does it end by “.co” instead of “.com”, e.g., http://abcnews.com.co?).
See our recent EMNLP-2018 publication for detail (joint work with researchers from MIT-CSAIL and students from the Sofia University): http://aclweb.org/anthology/D18-1389
We have extended the system to model factuality and left-vs-right bias jointly as they are correlated, i.e., center media tend to be more factual, while partisan websites are less so. This has been shown to hold in general, and it is also the case for our data, which is based on the Media Bias/Fact Check:
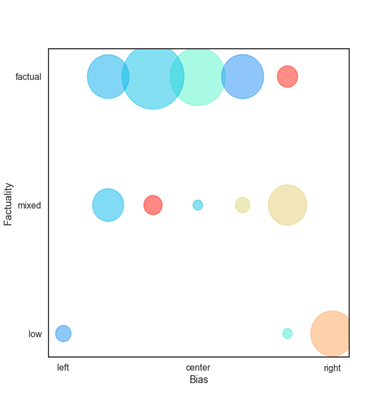
Finally, we are currently extending the system to handle news outlets in different languages, and initial experiments have been carried out with Arabic, as well as some other languages including Hungarian, Italian, Turkish, Greek, French, German, Danish, and Macedonian. This is based on a language-independent model, and it can potentially handle many more languages.
The Tanbih Project
Characterizing media in terms of factuality of reporting and bias is part of a larger effort at QCRI. In particular, we are developing a news aggregator, Tanbih (meaning alert or precaution in Arabic), which lets users know what they are reading. It features media profiles, which include automatic predictions for the factuality of reporting and left/right bias, as well as estimations of the likelihood that a news article is propagandistic, among other features. In addition to a website, we are developing versions for a mobile phone that run on Android and iPhone.
You can learn more about the project here:
You can try the Web version here:
The App is in its early stages, but the plan for it is ambitious. It aims at helping users “step out of their bubble” and achieve a healthy “news diet”. In addition to the typical daily news feed as in Google News or FlipBoard, the app will find controversial topics and will help the readers step out of their bubble by showing them different viewpoints on the same topic, by informing them about the stance of an article with respect to a controversial topic, about the publisher/author in general (reliability, trustworthiness, biases, etc.), and also by providing background for the story.
We have a fully functional news aggergator:
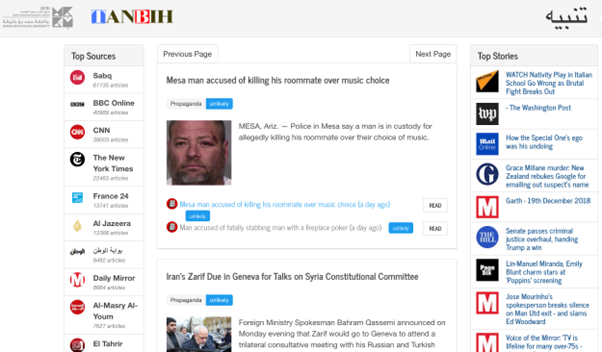
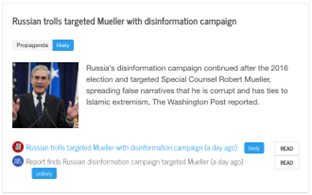
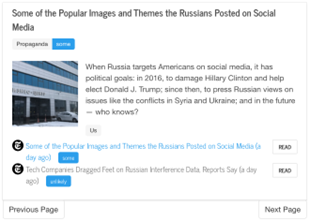
As people are reading the news, they see whether an article is likely to be propagandistic and they can also click on a media outlet icon and get information about the media profile. Thus, they can always know what they are reading. For example, here is the profile we have for Aljazeera: https://www.tanbih.org/media/5